.png?width=256&height=256&name=customer-service(1).png)



.png?width=64&height=64&name=calendrier(1).png)
.png?width=64&height=64&name=communique-de-presse(1).png)
.png?width=64&height=64&name=livre(1).png)
.png?width=64&height=64&name=blog(2).png)




It All Starts with a Medical Need
With a growing workload, a shortage of pathologists, and increasing demands for diagnostic completeness and precision, the challenges facing pathology are mounting. From the complexity of images and inter-observer variability to the continuous evolution of medical practices, patient-related stakes, and rising regulatory pressure, these factors all contribute to a significant cognitive burden for professionals.
In this context, artificial intelligence (AI) emerges as a powerful lever for improvement. It can automate certain tasks, bring greater objectivity, and boost efficiency. Rather than replacing human expertise, AI acts as a valuable support system—enhancing the reliability and, in some cases, the depth of diagnostic insights.
However, for an AI solution to be truly useful to pathologists, it must address a clearly identified medical need. Designing an algorithm always begins with a strategic reflection: what clinical problem are we trying to solve ? This step considers the medical relevance of the problem, its potential impact in practice, the availability of existing solutions, and the technical feasibility of the project. From there, the intended use of the tool is defined: will it save time? Improve precision? Provide new information?
It is also necessary to project the use of this tool within the concrete context of its application: it must meet a clear medical need and be technically feasible, but must also integrate easily into the daily routine of physicians and remain economically viable. It is essential from the outset to consider the integration of this tool into the practitioner’s workflow, taking into account IT constraints and resources. The objective is to best orchestrate its adoption and operation in a way that preserves its value proposition under real-world conditions. It is by reconciling these various requirements that the AI algorithm becomes a truly effective tool in support of diagnosis.
Building a High-Quality Annotated Dataset
Once the need is well defined, the first concrete development step is to build a robust dataset. This involves collecting a large volume of representative images, covering various subtypes of pathologies and reflecting the diversity of preparation and scanning practices.
The more complex the intended algorithm, the more data is needed—sometimes thousands of images. These images must be high-quality: clear, artifact-free, and scanned at appropriate magnifications. However, their quality must meet routine clinical standards to ensure that the algorithm remains applicable and effective when used on real-world data.
Confidentiality and ethics are also essential: obtaining patient consent, de-identifying their data, and addressing issues of bias and fairness.
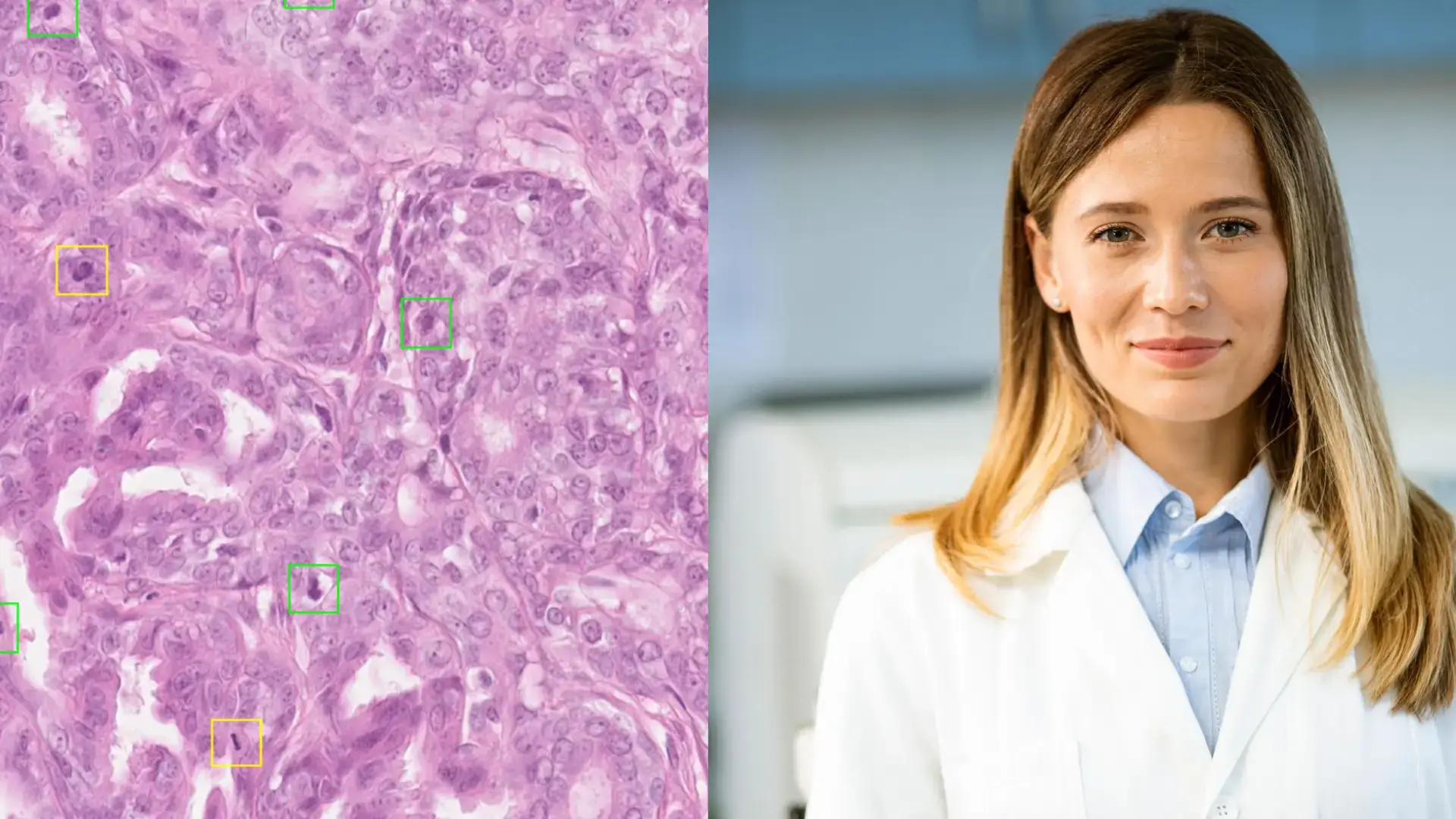
Finally, in the case of so-called “supervised” approaches, as described below, it is essential that the data be enriched with annotations that manually identify the relevant elements within each image so that the model can specifically take them into account (for example, a positive cell, a negative cell, a mitosis, or a region identified as “tumor”). These annotations must be performed rigorously in order to define what is known as the “ground truth.” At times, the complexity of the task and the subjectivity of the annotator make this ground truth difficult to establish. It is therefore typically carried out by an expert or, more reliably, through consensus among multiple pathologists. It may also rely on special stains or diagnostic tests. In certain cases, patient clinical follow-up can help confirm the diagnosis, further enhancing the quality of the annotation.
This is a long and meticulous but essential task, as the algorithm learns precisely from what it is shown. Inaccurate annotation can lead to a biased or ineffective AI.

Model Selection and Algorithm Training
Once the annotated images have been collected, the next step is to choose the appropriate type of artificial intelligence model, depending on what the algorithm is expected to do. In digital pathology, several approaches are possible:
- Classification: The model learns to recognize different image types, for example, distinguishing benign from malignant cancers.
- Detection: The model identifies specific areas within an image, such as suspicious regions.
- Segmentation: The model isolates structures within the image, such as cells or tissues.
- Image generation: The model creates synthetic images that can be used for training or simulating rare scenarios.
Then comes the training method: - Fully supervised: This is the most interpretable and transparent training method for users, which helps build trust in the model. However, it requires a significant investment of time and resources due to the large volume of precise annotations needed.
- Weakly supervised: images have little or no annotation. The algorithm learns from general labels (like a global diagnosis), which saves time, but the AI might focus on elements different from those a human would prioritize.
- Unsupervised: no annotations are provided. The model independently finds patterns and similarities in the data. This method is useful for exploratory analysis but lacks transparency and is not yet suitable for clinical use.
From Research to Product : Scaling Up
Developing a strong algorithm in a lab is only the beginning. To be used in clinical practice, an AI tool must undergo multiple levels of rigorous validation.
The first step is analytical validation, or internal validation. This involves testing the model on the training dataset to assess its technical performance. Key metrics include sensitivity (ability to identify positive cases) and specificity (ability to avoid false positives). This ensures the algorithm is technically reliable.
Next comes clinical validation, or external validation. Here, the model is tested on new data from different hospitals or labs to evaluate its ability to generalize-i.e., to maintain performance in new, real-world conditions.
These two validation steps help assess and demonstrate both the analytical and clinical performance of the algorithm. They directly impact the quality of care and patient safety and are essential to obtaining regulatory approval in Europe.
Finally, the last step is to demonstrate the clinical utility of the model. It is not enough for the algorithm to perform well, there must be evidence that it brings real benefits to patient care. This can be shown through prospective trials, which follow patients over time to observe the tool’s impact in real-world settings, such as hospitals or pathology laboratories.
When these benefits are clearly demonstrated, it becomes possible to initiate the regulatory process for approval by the relevant health authorities in each jurisdiction. The first step is typically to obtain certification as a medical device (MD), in accordance with applicable regulations—such as CE marking under the In Vitro Diagnostic Regulation (IVDR) in the European Union, or FDA clearance under applicable pathways in the United States—for diagnostic support tools intended for routine clinical use. A second step, which is distinct and not always pursued, may involve submitting a request for reimbursement or coverage, depending on the healthcare system, the type of AI tool, and its demonstrated value proposition. To date, reimbursement of AI-powered medical devices in pathology remains extremely rare globally, with only a few precedents in select jurisdictions.
From design to clinical validation, each step is essential to ensure the reliability and usefulness of an AI algorithm in digital pathology. At the end of this journey, AI becomes a true ally for both clinicians and patients.

Stay Connected! 
Stay ahead of the curve in digital pathology and AI innovation! Follow us on LinkedIn to stay updated with the latest trends, insights, and breakthroughs in healthcare technology. Join the conversation and be part of the future of pathology! 🚀🔍 #FollowUs #DigitalPathology #Innovation #TribunHealth